Have you ever witnessed a piece of technology so grand that you knew it would change the world eventually? When digital cameras hit the mass market, I knew your traditional 35mm camera was dead. Sure, the quality of film photography was better in the beginning, and I still think film takes better pictures. But for everyday snapshots, you just can't beat that little digital camera.
During Christmas, my Mother-in-Law mentioned that she couldn't find 35mm film at the grocery store anymore. I thought nah, people buy film for the Holidays, they're just out. So on our shopping adventures yesterday, I stopped in the photography section of my local Wal-Mart to pick her up some film. They had a couple rolls of Advantix film and a four pack of 800 speed 35mm and that was it. Lots of throw-away cameras, but no film. Three do-it-yourself kiosks for downloading your pictures, but no film.
Huh, maybe the mega-grocery store would have some. Nope, same deal. Lots of disposable cameras, a couple rolls of Advantix, and a few four-packs of 800 speed 35mm. Not even an empty peg where the normal speed film would go.
Now we were on a mission to find either 200 or 400 speed film. Our next stop took us to our local mega-drug store and sure enough they had film. Not a wide selection, mind you, but they had enough to choose.
So what's the significance? Certainly film's not going away. But in the very near future, I'm expecting that the only place you'll be able to pickup film is at a camera shop. I think everything film related becomes a botique item and may actually revive many camera shops that have been wondering about how to survive in a digital world. In the mean time, I wonder if there is a market for Cannon AE-1's on ebay....
Thursday, December 27, 2007
Thursday, December 20, 2007
Picking a WYSIWYG Editor for Drupal
I've been doing a lot of research lately into setting up Drupal as a Content Management System. One of Drupal's shortcomings (by design) is the current production version doesn't have a WYSIWYG editor. The lack of a visual editor is not a big deal since there are several editors you can just plug-in (more or less) as a module.
The first editor I tried was TinyMCE by Moxicode. I originally got this editor setup in short time with help from Howard Rogers. It was easy to install and did most of what I wanted. However, as I got a little more sophisticated, I started using grids and images more and more. Most of the time my entries came out OK, but every now and then my theme was all messed up because of a misplaced HTML tag. Not a major hassle for me, but if I was going to open my website up to non-technical users, I couldn't risk them unintentionally screwing it up.
So I searched a little more and came up with FCKEditor. It's a little more difficult to install than TinyMCE as you have to go in and modify a PHP file, but the instructions are clear and simple. It also comes with everything you need out of the box and there is little extra configuration that you have to do. However, with that ease of use comes a lack of granularity. So it's a trade-off. Best of all, the grids and images work great with my chosen theme.
For now, I'm sticking with FCKEditor.
The first editor I tried was TinyMCE by Moxicode. I originally got this editor setup in short time with help from Howard Rogers. It was easy to install and did most of what I wanted. However, as I got a little more sophisticated, I started using grids and images more and more. Most of the time my entries came out OK, but every now and then my theme was all messed up because of a misplaced HTML tag. Not a major hassle for me, but if I was going to open my website up to non-technical users, I couldn't risk them unintentionally screwing it up.
So I searched a little more and came up with FCKEditor. It's a little more difficult to install than TinyMCE as you have to go in and modify a PHP file, but the instructions are clear and simple. It also comes with everything you need out of the box and there is little extra configuration that you have to do. However, with that ease of use comes a lack of granularity. So it's a trade-off. Best of all, the grids and images work great with my chosen theme.
For now, I'm sticking with FCKEditor.
Wednesday, December 19, 2007
Upgrading to R12
Upgrading Oracle Applications is never an easy process. I like to test my upgrades both for completeness as well as performance so I can give my users a semi-accurate picture of how long things will take.
I'm doing a direct upgrade from 11.5.9.CU2 to R12 (probably CU3). I got to the point where the db objects are upgraded and received the following message:
Any guesses on how long this upgrade run will take?
I'm doing a direct upgrade from 11.5.9.CU2 to R12 (probably CU3). I got to the point where the db objects are upgraded and received the following message:
There are now 126521 jobs remaining (current phase=A3):OK, then. When I upgraded from 11.5.3 to 11.5.9, the object upgrade portion took about 26 hours, but I was on a slower box (Sun 2x900 with 8G RAM) and Oracle 9.2.0.7. Now I'm on a Sun 4x1200 with 16G of RAM and Oracle 10.2.0.3. This is only my first attempt at upgrading and I'll look at the AWR stats after to see where my bottlenecks were during the upgrade.
6 running, 951 ready to run and 125564 waiting
Any guesses on how long this upgrade run will take?
Monday, December 10, 2007
A properly constructed voicemail, Part I
"Hi, this is Fred, the DB is down. Call me.", is not an appropriate message.
First of all, Fred who? Fred in accounting or Fred in customer service. It makes a difference to me.
Which DB is down? OK, so you don't know the exact database, tell me the application you are using.
Oh, and Fred, leave me a number where I can get back to you. It's 2:00 in the morning and I'm nowhere near a computer to lookup your number.
A properly constructed message would have been:
"Hi, this is Fred in accounting. I'm having a problem logging into Oracle Financials and am getting a 404 error message. Please call me at extension 1234."
First of all, Fred who? Fred in accounting or Fred in customer service. It makes a difference to me.
Which DB is down? OK, so you don't know the exact database, tell me the application you are using.
Oh, and Fred, leave me a number where I can get back to you. It's 2:00 in the morning and I'm nowhere near a computer to lookup your number.
A properly constructed message would have been:
"Hi, this is Fred in accounting. I'm having a problem logging into Oracle Financials and am getting a 404 error message. Please call me at extension 1234."
Friday, November 02, 2007
Bugs, bugs, and more bugs
You may have noticed that my blog postings have been pretty sparse lately. I get that way when I have to work on Oracle Applications. Whenever I am doing an Apps project I end up having to read about 2000 pages of documentation that point to another 100 documents on Metalink. Not much to blog about there.
By the time I am done reading, the whole process is so utterly complex that I end up putting my own process together and pulling the parts relavent to my installation into a single document.
So I've been working on my master document for about two weeks now and I'm finally ready to install a fresh version of R12 on my pre-test box. Now, I fully expect something to crash and burn in this environment and I'll have to wipe it out and start over in a couple days.
I fired up the installer and right away it encountered a java exception; "java.lang.NullPointerException".
Hmm, maybe I have the CD's staged in the wrong location. So I take another two hours and restage the CDs.
"java.lang.NullPointerException" again.
So I check my DISPLAY and make sure I can start xclock. No problem.
Then I look on Metalink and sure enough, I ran into a bug. The install software that shipped has a bug in it. Good old bug 5972626.
Did anyone even test this stuff before it went on CD? It's bad enough that my standard 10gR2 install has 23 patches applied, but a bug so it doesn't even install?
Why am I surprised?
By the time I am done reading, the whole process is so utterly complex that I end up putting my own process together and pulling the parts relavent to my installation into a single document.
So I've been working on my master document for about two weeks now and I'm finally ready to install a fresh version of R12 on my pre-test box. Now, I fully expect something to crash and burn in this environment and I'll have to wipe it out and start over in a couple days.
I fired up the installer and right away it encountered a java exception; "java.lang.NullPointerException".
Hmm, maybe I have the CD's staged in the wrong location. So I take another two hours and restage the CDs.
"java.lang.NullPointerException" again.
So I check my DISPLAY and make sure I can start xclock. No problem.
Then I look on Metalink and sure enough, I ran into a bug. The install software that shipped has a bug in it. Good old bug 5972626.
Did anyone even test this stuff before it went on CD? It's bad enough that my standard 10gR2 install has 23 patches applied, but a bug so it doesn't even install?
Why am I surprised?
Thursday, November 01, 2007
Posting Pictures to a phpBB forum
I run across this situation almost daily. Somebody needs to post either a screen shot or a picture (same thing) to a phpBB forum and they can't figure out how to do it.
First, you need a third party picture hosting service. I personally prefer Flickr, but there are others like Photobucket and SmugMug out there that allow you to host your pictures for free. You can even host it on your blog on blogger.com! My example will be using Flickr, but really all you need is a URL to the actual image file.
Upload your photo to Flickr. If you don't have a Yahoo account, you can create one for free.
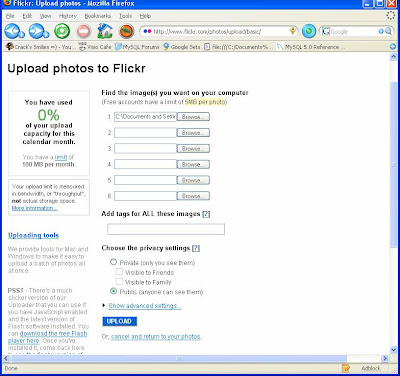
Click "Upload Photo" and either type in the name of your picture file (complete path) or use the "Browse" button to find it. Make sure the "Public" radio button is selected and click "Upload".
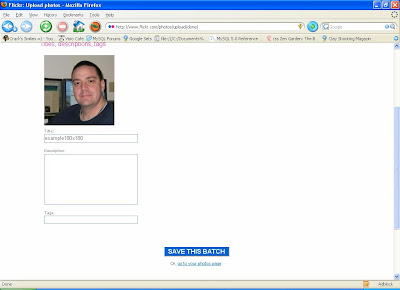
Your picture will be uploaded and displayed when it is done. Now, click "Save this Batch".
All your pictures are now displayed.
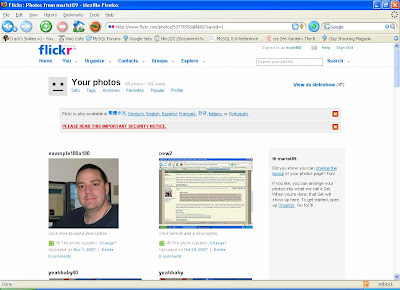
Click on the picture you just uploaded and then click on the "All Sizes" button:
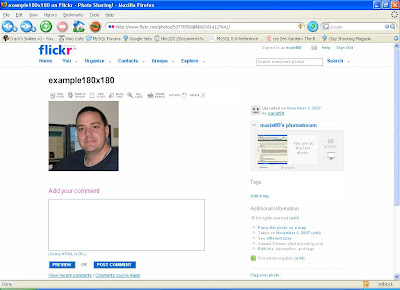
At the bottom of that page, you will see "2. Grab the photo's URL". Copy this URL into your buffer by highlighting it and pressing CTRL+C.
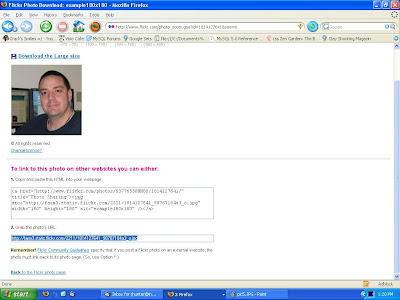
Now, you're done with Flickr. Next, go to the forum you want to post in and compose a message. Type in the text you wish. When you get to the point you want to insert your image, you will enclose the URL from the step above within [img][/img] tags:
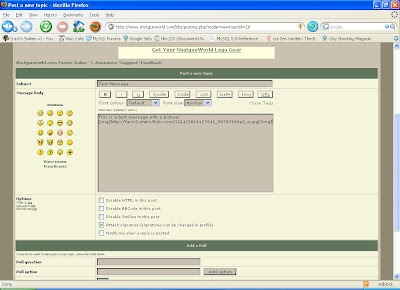
Post your message and the picture will show up inline:

First, you need a third party picture hosting service. I personally prefer Flickr, but there are others like Photobucket and SmugMug out there that allow you to host your pictures for free. You can even host it on your blog on blogger.com! My example will be using Flickr, but really all you need is a URL to the actual image file.
Upload your photo to Flickr. If you don't have a Yahoo account, you can create one for free.

Click "Upload Photo" and either type in the name of your picture file (complete path) or use the "Browse" button to find it. Make sure the "Public" radio button is selected and click "Upload".

Your picture will be uploaded and displayed when it is done. Now, click "Save this Batch".

All your pictures are now displayed.

Click on the picture you just uploaded and then click on the "All Sizes" button:

At the bottom of that page, you will see "2. Grab the photo's URL". Copy this URL into your buffer by highlighting it and pressing CTRL+C.

Now, you're done with Flickr. Next, go to the forum you want to post in and compose a message. Type in the text you wish. When you get to the point you want to insert your image, you will enclose the URL from the step above within [img][/img] tags:

Post your message and the picture will show up inline:

Wednesday, September 12, 2007
There's more than one way to skin a cat
We're off on an adventure trying to figure out why one of our 9.2.0.5 databases has poor response time during a certain period. During the investigation, I came across a process that was executing a query that had a function call in it. It wasn't our problem, but was interesting none the less.
I started tracing the user's session and found that for every row in table T the query was executing function getCount (the names have been changed and the function simplified to clarify the example).
OK, seams reasonable enough, right. But inside getCount() was a query:
Ah, here's the query that showed up in the trace as being the top dog.
"Hmm, let me just fix this and let the developer know how to fix his problem" I thought to myself, "he'll appreciate it."
So I suggested the following query for the fix:
The number of logical reads was much better and the wall clock response time was much better as well. Perfectly suitable solution.
Well, proving that DBAs don't know anything about how to write code, the fix ended up being:
OK, that works. No reason to do something the easy way when you can write code and do it the cool way.
Addition: As Gary points out in the coments, there is a potential in the new function for records with both a '3' AND a '7' to be picked up twice. In my actual data, there is a business rule that makes sure that doesn't happen, but in general it is an issue.
I started tracing the user's session and found that for every row in table T the query was executing function getCount (the names have been changed and the function simplified to clarify the example).
SELECT x, getcount()
FROM t
OK, seams reasonable enough, right. But inside getCount() was a query:
create or replace function getcount return integer
as
c integer;
begin
select count(*) into c from xyz where (code1='7' or code2='3');
return c;
end;
Ah, here's the query that showed up in the trace as being the top dog.
SELECT COUNT(*)
FROM
XYZ WHERE (CODE1='7' OR CODE2='3')
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 1 2.47 8.55 57428 63059 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 3 2.47 8.55 57428 63059 0 1
"Hmm, let me just fix this and let the developer know how to fix his problem" I thought to myself, "he'll appreciate it."
So I suggested the following query for the fix:
select count(*) from (
select id from xyz where code1='7'
union
select id from xyz where code2='3'
)
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.05 0.05 0 666 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.05 0.05 0 666 0 1
The number of logical reads was much better and the wall clock response time was much better as well. Perfectly suitable solution.
Well, proving that DBAs don't know anything about how to write code, the fix ended up being:
create or replace function getcount return integer
as
cursor c1 is select count(*) cnt from xyz where code1='7';
cursor c2 is select count(*) cnt from xyz where code2='3';
t integer := 0;
begin
for i in c1 loop
t := t+i.cnt;
end loop;
for i in c2 loop
t := t+i.cnt;
end loop;
return t;
end;
/
SELECT COUNT(*) CNT
FROM
XYZ WHERE CODE2='3'
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.03 0.03 0 387 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.03 0.03 0 387 0 1
SELECT COUNT(*) CNT
FROM
XYZ WHERE CODE1='7'
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.00 0.00 0 0 0 0
Execute 1 0.00 0.00 0 0 0 0
Fetch 2 0.03 0.02 0 279 0 1
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 4 0.03 0.02 0 279 0 1
OK, that works. No reason to do something the easy way when you can write code and do it the cool way.
Addition: As Gary points out in the coments, there is a potential in the new function for records with both a '3' AND a '7' to be picked up twice. In my actual data, there is a business rule that makes sure that doesn't happen, but in general it is an issue.
Monday, September 10, 2007
Inexcusable Response
Back in April I filed a TAR on an ORA-00904 error I was getting when I called dbms_stats.gather_index_stats() in 9.2.0.8:
No problem, I already figured out that if I used ANALYZE TABLE I could work around the error. After about 3 weeks of traces and going back and forth, Oracle acknowledge it was bug 3078144 and was fixed on 10.2.
I requested a backport to my version. After all, I was on a supported version so I figured it wouldn't even be an issue. While I was planning on going to 10.2 eventually, it wasn't in the immediate plans. After the first month, I pinged support to see where my backport was.
"Oh, development denied it because it is a Level 3 SR."
Hmm, that's the game we're playing, eh?
"Well, it's happening every day now and affecting my business", I replied. OK, maybe a little fib, but lets see where it goes.
We agreed to raise it to a Level 2 SR.
Another month went by so I followed up again. Still with development. At this point we started planning the migration to 10.2 (not because of this TAR, but we are gluttons for punishment). It would be a race to see if I got my bug fix or my db upgraded to 10.2 first.
About two weeks ago, I decided to ratchet up the pressure; I "duty managed" the TAR. I got the nicest duty manager who knew how to talk the talk, but I wasn't buyin' what he was sellin'.
"I will give you a call within three business days to let you know the status of the bug fix." was his final reply. A week went by with no update.
Well, this past weekend I won - the database was upgraded to 10.2.0.3+. While I was tempted to keep the TAR open just to see how long it took to resolve, I decided honor was the better part of valor and closed the tar indicating we had upgraded.
I bet I don't get a satisfaction survey on this one.
SQL> exec dbms_stats.gather_index_stats('SCOTT','TIGER_CK');
BEGIN dbms_stats.gather_index_stats('SCOTT','TIGER_CK'); END;
*
ERROR at line 1:
ORA-00904: : invalid identifier
ORA-06512: at "SYS.DBMS_STATS", line 8557
ORA-06512: at "SYS.DBMS_STATS", line 8577
ORA-06512: at line 1No problem, I already figured out that if I used ANALYZE TABLE I could work around the error. After about 3 weeks of traces and going back and forth, Oracle acknowledge it was bug 3078144 and was fixed on 10.2.
I requested a backport to my version. After all, I was on a supported version so I figured it wouldn't even be an issue. While I was planning on going to 10.2 eventually, it wasn't in the immediate plans. After the first month, I pinged support to see where my backport was.
"Oh, development denied it because it is a Level 3 SR."
Hmm, that's the game we're playing, eh?
"Well, it's happening every day now and affecting my business", I replied. OK, maybe a little fib, but lets see where it goes.
We agreed to raise it to a Level 2 SR.
Another month went by so I followed up again. Still with development. At this point we started planning the migration to 10.2 (not because of this TAR, but we are gluttons for punishment). It would be a race to see if I got my bug fix or my db upgraded to 10.2 first.
About two weeks ago, I decided to ratchet up the pressure; I "duty managed" the TAR. I got the nicest duty manager who knew how to talk the talk, but I wasn't buyin' what he was sellin'.
"I will give you a call within three business days to let you know the status of the bug fix." was his final reply. A week went by with no update.
Well, this past weekend I won - the database was upgraded to 10.2.0.3+. While I was tempted to keep the TAR open just to see how long it took to resolve, I decided honor was the better part of valor and closed the tar indicating we had upgraded.
I bet I don't get a satisfaction survey on this one.
Wednesday, September 05, 2007
 Cat with Bow Golf
Cat with Bow GolfTuesday, September 04, 2007
A dying breed?
I usually get a feel for "what's hot" in the marketplace by the number of books on the shelves at my favorite bookstore. A couple years ago there was six shelves at my Borders store filled with books on Oracle. Oracle for Dummies, PL/SQL, and scores of Certification books. I was quite surprised to find only three books on Oracle at the same store this past weekend.
MySQL still has some respect with about a 1/2 shelf. .Net clocked in with about 5 or 6 shelves with a smattering here and there of Java and the associated technologies. Good old Perl shared half a shelf with PHP. But I feel left behind because I don't know Excel Macros (about 12 shelves).
Maybe Oracle has really achieved a self-tuning, self-managing database and we don't need books anymore.
Please excuse me while I apply four more patches to my "up-to-date" 10.2.0.3 installation.
MySQL still has some respect with about a 1/2 shelf. .Net clocked in with about 5 or 6 shelves with a smattering here and there of Java and the associated technologies. Good old Perl shared half a shelf with PHP. But I feel left behind because I don't know Excel Macros (about 12 shelves).
Maybe Oracle has really achieved a self-tuning, self-managing database and we don't need books anymore.
Please excuse me while I apply four more patches to my "up-to-date" 10.2.0.3 installation.
Wednesday, August 22, 2007
Deadlocks
Good old ORA-00060: deadlock detected while waiting for resource. There's really two main causes for an ORA-00060 error; bad application logic or unindexed foreign keys.
The classic example of a deadlock is userA updating table X and then table Y while userB updates table Y and then table X. Oracle kills one of the users, rolls back his transaction, throws an error to the alert.log and everybody else moves on. As DBAs, we look at these errors, forward them to the appropriate developer and forget about them.
The second most prevalent cause of ORA-00060 errors is unindexed foreign keys. You can check out Oracle's explanation and there are a ton of scripts that will help you diagnose this situation. I personally use a variation of Tom Kyte's script but there are others such as this one.
I know, you're asking yourself "So What? Everybody knows about deadlocks."
Be patient grasshopper, there's more to the story.
A couple weeks ago we started getting ORA-00060 error messages every now and then on a 10.2.0.3 database that rarely received this type of message before. And then some of our critical processes slowed down. And then we started getting about 12 ORA-00060 errors a day.
At first, we attacked it as two separate problems; the ORA-00060 error and performance. One DBA started decoding the trace files from the deadlocks informing the developers of which objects were involved and the data involved. The weird part was the deadlock was occurring on an INSERT statement.
At the same time, I started tracing the slow processes and found that a great majority of time was being spent on "enq: TM - contention" waits. We then ran an AWR report and found that the top wait was "enq: TM - contention" and we knew we had a problem.
The wait event and the ORA-00060 together lead us to an unindexed FK. However, all the scripts we used indicated the fks were indexed. We started disabling the FKs one by one (for the two tables involved in the majority of the deadlocks). After one particular FK was disabled, all our "enq: TM - contention" waits went away and things were back to normal.
Oracle support directed us to bug 6053354 which isn't really a bug because of bug 6066587. Sure enough, the conditions in 6053354 existed in our database. We turned the tablespaces to read-write and re-enabled the FK with no adverse effects.
The moral of the story is follow your instincts up to a point, but every now and then something really freaky is going on.
The classic example of a deadlock is userA updating table X and then table Y while userB updates table Y and then table X. Oracle kills one of the users, rolls back his transaction, throws an error to the alert.log and everybody else moves on. As DBAs, we look at these errors, forward them to the appropriate developer and forget about them.
The second most prevalent cause of ORA-00060 errors is unindexed foreign keys. You can check out Oracle's explanation and there are a ton of scripts that will help you diagnose this situation. I personally use a variation of Tom Kyte's script but there are others such as this one.
I know, you're asking yourself "So What? Everybody knows about deadlocks."
Be patient grasshopper, there's more to the story.
A couple weeks ago we started getting ORA-00060 error messages every now and then on a 10.2.0.3 database that rarely received this type of message before. And then some of our critical processes slowed down. And then we started getting about 12 ORA-00060 errors a day.
At first, we attacked it as two separate problems; the ORA-00060 error and performance. One DBA started decoding the trace files from the deadlocks informing the developers of which objects were involved and the data involved. The weird part was the deadlock was occurring on an INSERT statement.
At the same time, I started tracing the slow processes and found that a great majority of time was being spent on "enq: TM - contention" waits. We then ran an AWR report and found that the top wait was "enq: TM - contention" and we knew we had a problem.
The wait event and the ORA-00060 together lead us to an unindexed FK. However, all the scripts we used indicated the fks were indexed. We started disabling the FKs one by one (for the two tables involved in the majority of the deadlocks). After one particular FK was disabled, all our "enq: TM - contention" waits went away and things were back to normal.
Oracle support directed us to bug 6053354 which isn't really a bug because of bug 6066587. Sure enough, the conditions in 6053354 existed in our database. We turned the tablespaces to read-write and re-enabled the FK with no adverse effects.
The moral of the story is follow your instincts up to a point, but every now and then something really freaky is going on.
Tuesday, August 21, 2007
Back when the internet was fun...
Do you remember way back to 2005 when the internet was fun?
Wanted to check the progress of the NCAA tournament during the day? Just go to http://www.espn.com and your browser refreshes automatically as the action happens.
Read some industry chit-chat during your lunch hour? Open up your favorite news aggregator and read away.
Two years ago I wouldn't have thought twice about forwarding a funny email to friends & family.
Try to go to http://www.espn.com today and you'll likely have to "justify the business need" to three levels of management to get your scores.
My RSS newsfeeds quit working a couple weeks ago. Doesn't matter that 90% of them are industry related, they're not business appropriate.
I stopped forwarding emails to some friends and family because I was tired of getting the bounce messages from their email filter. It's just not the same when you have to tell the joke over the phone and explain why 18 goes into 54 more times than 54 goes into 18.
Ah, the price of progress.
Wanted to check the progress of the NCAA tournament during the day? Just go to http://www.espn.com and your browser refreshes automatically as the action happens.
Read some industry chit-chat during your lunch hour? Open up your favorite news aggregator and read away.
Two years ago I wouldn't have thought twice about forwarding a funny email to friends & family.
Try to go to http://www.espn.com today and you'll likely have to "justify the business need" to three levels of management to get your scores.
My RSS newsfeeds quit working a couple weeks ago. Doesn't matter that 90% of them are industry related, they're not business appropriate.
I stopped forwarding emails to some friends and family because I was tired of getting the bounce messages from their email filter. It's just not the same when you have to tell the joke over the phone and explain why 18 goes into 54 more times than 54 goes into 18.
Ah, the price of progress.
Wednesday, July 18, 2007
Materialized View Tricks, NOT
While working on another problem, I found this interesting little tidbit with Materialized Views querying views on Oracle 10.2.0.3.
One one db, I have a table called xyz_rtab. The table structure doesn't really matter, it's just any table with a primary key. Then, I create a view on top of the table:
Why do that? Well, my table is not really a table in my environment. The view on top of the table is really refactoring a business object that is used by several systems but whose time has come to change. But it doesn't matter, for the purposes of this demonstration.
Next, I change dbs and create the database link I'll use to get this data.
Now, I query across that dblink to verify that I can actually see the data:
If I can query the data I should be able to create a mview, right? Lets try from the base table:
No problem, that's what we expect. Now lets try from the view:
Nice.
One one db, I have a table called xyz_rtab. The table structure doesn't really matter, it's just any table with a primary key. Then, I create a view on top of the table:
db2> create view xyz_v1 as select * from xyz_rtab;
View created.
Why do that? Well, my table is not really a table in my environment. The view on top of the table is really refactoring a business object that is used by several systems but whose time has come to change. But it doesn't matter, for the purposes of this demonstration.
Next, I change dbs and create the database link I'll use to get this data.
db1> create database link db2 using 'db2';
Database link created.
Now, I query across that dblink to verify that I can actually see the data:
db1> select count(*) from xyz_v1@db2;
COUNT(*)
----------
10
db1> select count(*) from xyz_rtab@db2;
COUNT(*)
----------
10
If I can query the data I should be able to create a mview, right? Lets try from the base table:
db1> create materialized view xyz_rtab_mview as select * from xyz_rtab@db2;
Materialized view created.
db1> exec dbms_mview.refresh(list=>'xyz_rtab_mview',method=>'C',atomic_refresh=>true);
PL/SQL procedure successfully completed.
No problem, that's what we expect. Now lets try from the view:
db1> create materialized view xyz_mv1 as select * from xyz_v1@db2;
create materialized view xyz_mv1 as select * from xyz_v1@db2
*
ERROR at line 1:
ORA-00942: table or view does not exist
ORA-06512: at "SYS.DBMS_SNAPSHOT_UTL", line 960
ORA-06512: at line 1
Nice.
Tuesday, July 10, 2007
No soup for you!
Have you read about Sprint cutting people off?
Seems as though Sprint is taking on the attitude that if you call them too much, you'll get dropped. Sounds like they think they're an insurance company not a phone carrier. I wonder if you only call twice in the life of your contract they'll give you a refund.
I deal with customer service departments every day. Lets face it, most customer service agents are great reading off a script, but the second you go off script they're clueless. And that's if you can even understand them.
Another point is that the way most customer service departments are setup, there's no incentive for the Customer Service Agent to actually solve your problem. They get financial incentives for closing problems, not solving problems. Ever open a trouble ticket with a certain database vendor and they work on it for a while and then say you have to open a new trouble ticket because they can't solve the problem?
Everybody knows (I know Tom, there are exceptions, but in general) that it costs more to attract customers than to keep them. I can't see many people actually wanting to talk to somebody half a world away on the phone 50 times a month. But that's just me.
Extra credit: Where does "No soup for you!" come from?
Seems as though Sprint is taking on the attitude that if you call them too much, you'll get dropped. Sounds like they think they're an insurance company not a phone carrier. I wonder if you only call twice in the life of your contract they'll give you a refund.
I deal with customer service departments every day. Lets face it, most customer service agents are great reading off a script, but the second you go off script they're clueless. And that's if you can even understand them.
Another point is that the way most customer service departments are setup, there's no incentive for the Customer Service Agent to actually solve your problem. They get financial incentives for closing problems, not solving problems. Ever open a trouble ticket with a certain database vendor and they work on it for a while and then say you have to open a new trouble ticket because they can't solve the problem?
Everybody knows (I know Tom, there are exceptions, but in general) that it costs more to attract customers than to keep them. I can't see many people actually wanting to talk to somebody half a world away on the phone 50 times a month. But that's just me.
Extra credit: Where does "No soup for you!" come from?
Monday, July 02, 2007
I think the database is broken
Below is a somewhat fictional somewhat realistic view of upgrades.
"I think the database is broken" was my first call this morning.
"OK, what error message are you getting?" was my reply. Since I knew we changed some things over the weekend, I figured something got left out and needed fixing.
"My process that normally takes 38 minutes is done in 3."
"OK, does it error out?"
"No."
"Do the results look right?"
"Yes."
"So why do you think it's broken?"
"Because it finished in 3 minutes."
"Well, we upgraded the database version this past weekend and put the database on a faster host, so that's probably the difference."
"But it used to take 38 minutes."
...long pause on the phone by me, expecting something else...
"I can slow it back down if that's what you want...."
On the flip side, I go to my developers to see how things are going and they report increases anywhere from 4-10 times faster depending on how much the db is being used. One savvy developer corners me and says something along the lines of "Can't we move this db to a faster host?"
"Huh? This is the almost latest, greatest, fastest host there is. You've got 3.0Ghz of Dual Core processing power underneath your db where before you had some clunky Sparc processors."
"You know there's 3.2Ghz processors out, right?"
"So, let me get this straight. You're 10 times faster than Friday, and you want to be 10.1 times faster?"
"Yup, that extra speed will really help."
"I need to get back to my office, call me if you have any problems."
"I think the database is broken" was my first call this morning.
"OK, what error message are you getting?" was my reply. Since I knew we changed some things over the weekend, I figured something got left out and needed fixing.
"My process that normally takes 38 minutes is done in 3."
"OK, does it error out?"
"No."
"Do the results look right?"
"Yes."
"So why do you think it's broken?"
"Because it finished in 3 minutes."
"Well, we upgraded the database version this past weekend and put the database on a faster host, so that's probably the difference."
"But it used to take 38 minutes."
...long pause on the phone by me, expecting something else...
"I can slow it back down if that's what you want...."
On the flip side, I go to my developers to see how things are going and they report increases anywhere from 4-10 times faster depending on how much the db is being used. One savvy developer corners me and says something along the lines of "Can't we move this db to a faster host?"
"Huh? This is the almost latest, greatest, fastest host there is. You've got 3.0Ghz of Dual Core processing power underneath your db where before you had some clunky Sparc processors."
"You know there's 3.2Ghz processors out, right?"
"So, let me get this straight. You're 10 times faster than Friday, and you want to be 10.1 times faster?"
"Yup, that extra speed will really help."
"I need to get back to my office, call me if you have any problems."
Wednesday, June 27, 2007
Why is it always the database?
When something is slow, why do we always point to the database? A computer system is so much more than "the application" and "the database". It's networks, routers, disks, memory, array controllers, middle-tiers, JDBC Drivers, Operating Systems, and client versions (which, usually comes round to "It's Oracle/MySQL, fix it"). Come to think of it, it's pretty amazing that we get decent performance at all.
Everybody is guilty of it from the novice to the experience person who knows better. Heck, I am sometimes guilty of it myself.
I'll get a call, "Application XYZ is slow, is the database OK?"
"Let me check."
A couple minutes later I indicate everything is fine on my end. I hear three days later that "XYZ was slow because of the database". Argh. Next time that person needs help tuning a query he'll get pointed to the documentation for EXPLAIN PLAN.
Why do we always point to the database first? Is it because the database is usually the guilty party? Or do we point fingers at what we don't understand?
Everybody is guilty of it from the novice to the experience person who knows better. Heck, I am sometimes guilty of it myself.
I'll get a call, "Application XYZ is slow, is the database OK?"
"Let me check."
A couple minutes later I indicate everything is fine on my end. I hear three days later that "XYZ was slow because of the database". Argh. Next time that person needs help tuning a query he'll get pointed to the documentation for EXPLAIN PLAN.
Why do we always point to the database first? Is it because the database is usually the guilty party? Or do we point fingers at what we don't understand?
Friday, June 15, 2007
Spike

Got a spike in hits on the blog in the last couple of days. I dug through the hits and found that a lot of people were coming from SearchOracle.com. I followed the most frequent URL and discovered that my post on Multiple Listeners had been linked to an article by Bill Cullen.
Thursday, May 24, 2007
What is going on in Oracle's QA department?
I've been an Oracle DBA since the days of 7.0.16 (on Netware, but that's a story for a different day). I'd like to think I have a decent amount of experience with Oracle and it's nuances. Sure, some things are quirky and don't work the way you think they should, but that's just getting used to the software. I can count on one hand the number of one-off patches I had to install over a base patchset in 7.x to 9.2. (I'm talking RDBMS here, not Oracle Apps.)
I specifically waited to move to 10g until it had been out a while. Our move to 10.2.0.3 has been quite disappointing. Sure, we did a lot of testing. But production is different than testing. After about 30 days of one db being live, we've had to install three one-off patches. And we just got slammed with two more in the last couple days to bring the total up to five. If we were on 10.2.0.0, I'd understand, but 10.2.0.3? Five freaking one-off patches.
C'mon Oracle, get your act together. We're trying to run a business here.
I specifically waited to move to 10g until it had been out a while. Our move to 10.2.0.3 has been quite disappointing. Sure, we did a lot of testing. But production is different than testing. After about 30 days of one db being live, we've had to install three one-off patches. And we just got slammed with two more in the last couple days to bring the total up to five. If we were on 10.2.0.0, I'd understand, but 10.2.0.3? Five freaking one-off patches.
C'mon Oracle, get your act together. We're trying to run a business here.
Friday, May 18, 2007
Oracle 10g upgrade gotcha
Everybody knows the Cost Based Optimizer needs decent statistics to figure out what his query plan should be. Sure, it takes time, but everybody does it. Some estimate, some compute, some think they have a better way.
After upgrading from 9.2.0.7 to 10.2.0.3, one of our systems suddenly slowed down. Not directly after the upgrade, but three days later. After some investigation, we found that some of the statistics had been estimated and not computed. That was pretty much a shock because my analyze method usually specifies estimate_percent=>null to make sure we compute. (Note, I already figured out that the default estimate_percent changed from 9i to 10g, so that wasn't it.)
I checked my custom analyze method and it reported that the table was never analyzed by me.
Hmmm, now it's getting real interesting. Just for kicks, I reran dbms_stats.gather_table_stats without an estimate_percent parameter and it estimated at about 8.3%. Aha! Must be using the AUTO_SAMPLE_SIZE for some reason.
So why?
Then I looked at the last_analyzed time of the tables that had been estimated. They all were run between 22:00 and 01:00. Aha, a schedule. Then I looked in dba_scheduler_jobs and there it was. A new job that Oracle automatically sets up to analyze stale objects.
When I checked in the morning, the objects didn't report as being stale. Then, after the day's data, Oracle decided the statistics were stale and analyzed the tables. When I went to gather statistics for stale objects the next morning, they had already been analyzed and weren't stale anymore. Except the statistics weren't optimal which made our queries "go bad".
Fortunately, there is a way you can disable this job just by tweaking the schedule.
After upgrading from 9.2.0.7 to 10.2.0.3, one of our systems suddenly slowed down. Not directly after the upgrade, but three days later. After some investigation, we found that some of the statistics had been estimated and not computed. That was pretty much a shock because my analyze method usually specifies estimate_percent=>null to make sure we compute. (Note, I already figured out that the default estimate_percent changed from 9i to 10g, so that wasn't it.)
I checked my custom analyze method and it reported that the table was never analyzed by me.
Hmmm, now it's getting real interesting. Just for kicks, I reran dbms_stats.gather_table_stats without an estimate_percent parameter and it estimated at about 8.3%. Aha! Must be using the AUTO_SAMPLE_SIZE for some reason.
So why?
Then I looked at the last_analyzed time of the tables that had been estimated. They all were run between 22:00 and 01:00. Aha, a schedule. Then I looked in dba_scheduler_jobs and there it was. A new job that Oracle automatically sets up to analyze stale objects.
When I checked in the morning, the objects didn't report as being stale. Then, after the day's data, Oracle decided the statistics were stale and analyzed the tables. When I went to gather statistics for stale objects the next morning, they had already been analyzed and weren't stale anymore. Except the statistics weren't optimal which made our queries "go bad".
Fortunately, there is a way you can disable this job just by tweaking the schedule.
BEGIN
DBMS_SCHEDULER.DISABLE('GATHER_STATS_JOB');
END;
/
Monday, May 14, 2007
Keywords
One thing that Statcounter provides me is how often certain keywords are found in my blog. Some of the more popular are:
- ORA-27054: I assume this is by people trying to backup using RMAN over NFS. I hope they found my problem and most importantly, my solution.
- Some combination of DB Links and ORA-01017: I'm sure people found my distributed issues with 9i and 10g working together. But that's not always the issue. If you are using what I call "unauthenticated" database links (no password in the definition) then the user authentication on both the source and remote database need to be the same. If we're talking an OS Authenticated user, then that user has to be OS Authenticated on both. If it's a regular db user, the passwords have to match.
- Lots of people looking for some varient of backup and methodology. I hope they found lots of info in the Backup Top 11, but I don't think I've ever described my backup methodology for Oracle. Maybe in a blog post in the future.
- I get lots of hits on the Quick and Dirty Backup for MySQL. Seems like a lot of people are looking for an easy solution to MySQL without having to fork over some cash for backup software.
- I also get lots of hits on The MySQL to an Oracle DBA series, but not too many through keyword searches.
- For the guy who's searching "mysql php round differently", I'd look at your datatype in the database to make sure you're using the proper number type.
- Looking for information on "_db_writer_flush_imu"? Better know what you're doing.
- Oh, and the person looking for "ingres porn server"...good luck on that.
Wednesday, May 09, 2007
Recognize your mistakes
I was reading an article in Business Week by Jack and Suzy Welch last night about the qualities of successful managers. Of the various qualities, one in particular stood out:
That's pretty good advice. Admit your mistakes, correct them, and move on. In my company, that's just the way it works. We don't waste time finger-pointing. If there was a failure, we put appropriate measures in place so it doesn't happen again and move on.
Gary Kaltbaum frequently says "Recognize your mistakes early." If you make a mistake, understand how you got into this situation and correct it as quickly as possible. Don't let your mistake fester and become a bigger problem down the road.
We would also add two other qualities to the must-have list. One is a heavy-duty resilience, a requirement because anyone who is really in the game messes up at some point. You're not playing hard enough if you don't! But when your turn comes, don't make the all-too-human mistake of thinking getting ahead is about minimizing what happened. The most successful people in any job always own the failures, learn from them, regroup, and then start again with renewed speed, vigor, and conviction.
That's pretty good advice. Admit your mistakes, correct them, and move on. In my company, that's just the way it works. We don't waste time finger-pointing. If there was a failure, we put appropriate measures in place so it doesn't happen again and move on.
Gary Kaltbaum frequently says "Recognize your mistakes early." If you make a mistake, understand how you got into this situation and correct it as quickly as possible. Don't let your mistake fester and become a bigger problem down the road.
Sunday, April 29, 2007
Two Years of So What?


I started this blog about two years ago. Never in my wildest dreams would have I thought that I would have over 200 regular subscribers and about 300 page views a day. In celebration of the Anniversary, I change the blog template to one of new standard blogger templates.
If only my IRA portfolio looked like this...
Friday, April 27, 2007
MySQL Pseudo-Partitioning, Part II
On advice of the MySQL She-BA, I wanted to see what performance I could get with MERGE tables. In my particular application I'm going to need the RI I get with InnoDB, so it's not a solution, but as long as I am investigating anyway...
Seems simple enough, let me the MERGE table over my existing tables:
Doh! That's right, got to change to MyISAM.
Lets see how it works now.
Whoa, that's pretty good, I could live with that. Lets compare the inline view of MyISAM tables vs. InnoDB tables:
Slightly faster than InnoDB, but not what I would call Significant. Definitely a viable option for partitioning in v5.0. Thanks to Sheeri for the top.
Seems simple enough, let me the MERGE table over my existing tables:
mysql> create table xyz_mt (
-> `id` bigint(10) NOT NULL default '0',
-> `report_dt` date default NULL,
-> `acct_id` varchar(8) default NULL,
-> `some_text` varchar(222) default NULL,
-> PRIMARY KEY (`id`)
-> ) ENGINE=MERGE UNION=(xyz_2007_01,xyz_2007_02,xyz_2007_03) ;
Query OK, 0 rows affected (0.08 sec)
mysql> select id, report_dt, acct_id
-> from xyz_mt
-> where report_dt ='2007-02-17'
-> and acct_id = 'X0000741';
ERROR 1168 (HY000): Unable to open underlying table which is differently defined or of non-MyISAM type or doesn't exists
Doh! That's right, got to change to MyISAM.
mysql> alter table xyz_2007_01 engine=MyISAM;
Query OK, 1000000 rows affected (25.42 sec)
Records: 1000000 Duplicates: 0 Warnings: 0
mysql> alter table xyz_2007_02 engine=MyISAM;
Query OK, 1000000 rows affected (17.82 sec)
Records: 1000000 Duplicates: 0 Warnings: 0
mysql> alter table xyz_2007_03 engine=MyISAM;
Query OK, 1000000 rows affected (18.84 sec)
Records: 1000000 Duplicates: 0 Warnings: 0
Lets see how it works now.
mysql> select id, report_dt, acct_id
-> from xyz_mt
-> where report_dt ='2007-02-17' and acct_id = 'X0000741';
+----------+------------+----------+
| id | report_dt | acct_id |
+----------+------------+----------+
| 20000741 | 2007-02-17 | X0000741 |
| 20967398 | 2007-02-17 | X0000741 |
+----------+------------+----------+
2 rows in set (2.43 sec)
Whoa, that's pretty good, I could live with that. Lets compare the inline view of MyISAM tables vs. InnoDB tables:
mysql> select * from (
-> select id, report_dt, acct_id from xyz_2007_01
-> union all
-> select id, report_dt, acct_id from xyz_2007_02
-> union all
-> select id, report_dt, acct_id from xyz_2007_03) t
-> where report_dt ='2007-02-17' and acct_id = 'X0000741';
+----------+------------+----------+
| id | report_dt | acct_id |
+----------+------------+----------+
| 20000741 | 2007-02-17 | X0000741 |
| 20967398 | 2007-02-17 | X0000741 |
+----------+------------+----------+
2 rows in set (15.17 sec)
Slightly faster than InnoDB, but not what I would call Significant. Definitely a viable option for partitioning in v5.0. Thanks to Sheeri for the top.
Thursday, April 26, 2007
MySQL Pseudo-partitioning
Got a MySQL project that needs a partitioned table. It's the ideal candidate really. Historical data that naturally would be partitioned by date. I need to keep an active window of data and delete old data quickly without doing DML.
Except partitioning is in 5.1 (more on that later) and I'm on 5.0.
One way I would overcome this limitation in Oracle Standard Edition would be to have multiple tables that hold a month worth of data and put a view on top of them. My users might notice a slight performance degradation, but it would be worth it to drop the data quickly.
So, I tried the same experiment in MySQL. I created three tables of this format:
And then I stuffed them with a million rows each. If I query a particular piece of data on a particular date, I expect to use the "xyz_rdt_acct*" index.
OK, I'm looking for two rows in the 2007_01 "partition". Lets create a view on top of those tables to present one interface for queries.
And now we query from the view.
Hmmm, that's not cool. 44 seconds to retrieve two rows. Lets try a sub-query just for kicks.
About the same, but a little bit better. Lets see what is going on.
Ah, three full table scans. Hmm, wonder why it's doing that. Lets do the same for the inline view.
Basically the same thing. Lets see what happens if I only get the fields I want in the sub-query.
Well, look at that. 16 seconds still isn't great, but at least the query is using the indexes.
Lets create a view using the same logic.
Performance is consistent at least.
Plan is consistent as well. Still, not a solution for me, but thought you might be interested in the findings.
The more I learn, the more questions I have. Tomorrow, I test partitioning on 5.1 beta.
Except partitioning is in 5.1 (more on that later) and I'm on 5.0.
One way I would overcome this limitation in Oracle Standard Edition would be to have multiple tables that hold a month worth of data and put a view on top of them. My users might notice a slight performance degradation, but it would be worth it to drop the data quickly.
So, I tried the same experiment in MySQL. I created three tables of this format:
CREATE TABLE `xyz_2007_01` (
`id` bigint(10) NOT NULL default '0',
`report_dt` date default NULL,
`acct_id` varchar(8) default NULL,
`some_text` varchar(222) default NULL,
PRIMARY KEY (`id`),
KEY `xyz_rdt_acct_2007_01` (`report_dt`,`acct_id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1
And then I stuffed them with a million rows each. If I query a particular piece of data on a particular date, I expect to use the "xyz_rdt_acct*" index.
mysql> select id, report_dt, acct_id
-> from xyz_2007_01
-> where report_dt ='2007-02-17'
-> and acct_id = 'X0000741';
Empty set (0.00 sec)
mysql> select id, report_dt, acct_id
-> from xyz_2007_02
-> where report_dt ='2007-02-17'
-> and acct_id = 'X0000741';
+----------+------------+----------+
| id | report_dt | acct_id |
+----------+------------+----------+
| 20000741 | 2007-02-17 | X0000741 |
| 20967398 | 2007-02-17 | X0000741 |
+----------+------------+----------+
2 rows in set (0.01 sec)
mysql> select id, report_dt, acct_id
-> from xyz_2007_03
-> where report_dt ='2007-02-17'
-> and acct_id = 'X0000741';
Empty set (0.00 sec)
OK, I'm looking for two rows in the 2007_01 "partition". Lets create a view on top of those tables to present one interface for queries.
mysql> create view xyz as
-> select * from xyz_2007_01
-> union all
-> select * from xyz_2007_02
-> union all
-> select * from xyz_2007_03
-> ;
Query OK, 0 rows affected (0.00 sec)
And now we query from the view.
mysql> select id, report_dt, acct_id from xyz where report_dt ='2007-02-17' and acct_id = 'X0000741';
+----------+------------+----------+
| id | report_dt | acct_id |
+----------+------------+----------+
| 20000741 | 2007-02-17 | X0000741 |
| 20967398 | 2007-02-17 | X0000741 |
+----------+------------+----------+
2 rows in set (44.36 sec)
Hmmm, that's not cool. 44 seconds to retrieve two rows. Lets try a sub-query just for kicks.
mysql> select id, report_dt, acct_id from (
-> select * from xyz_2007_01
-> union all
-> select * from xyz_2007_02
-> union all
-> select * from xyz_2007_03) t
-> where t.report_dt ='2007-02-17'
-> and t.acct_id = 'X0000741';
+----------+------------+----------+
| id | report_dt | acct_id |
+----------+------------+----------+
| 20000741 | 2007-02-17 | X0000741 |
| 20967398 | 2007-02-17 | X0000741 |
+----------+------------+----------+
2 rows in set (33.47 sec)
About the same, but a little bit better. Lets see what is going on.
mysql> explain select id, report_dt, acct_id from xyz where report_dt ='2007-02-17' and acct_id = 'X0000741';
+----+--------------+--------------+------+---------------+------+---------+------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------+--------------+------+---------------+------+---------+------+---------+-------------+
| 1 | PRIMARY | derived2 | ALL | NULL | NULL | NULL | NULL | 3000000 | Using where |
| 2 | DERIVED | xyz_2007_01 | ALL | NULL | NULL | NULL | NULL | 788670 | |
| 3 | UNION | xyz_2007_02 | ALL | NULL | NULL | NULL | NULL | 1014751 | |
| 4 | UNION | xyz_2007_03 | ALL | NULL | NULL | NULL | NULL | 1096175 | |
|NULL | UNION RESULT | union2,3,4 | ALL | NULL | NULL | NULL | NULL | NULL | |
+----+--------------+--------------+------+---------------+------+---------+------+---------+-------------+
5 rows in set (43.18 sec)
Ah, three full table scans. Hmm, wonder why it's doing that. Lets do the same for the inline view.
mysql> explain select id, report_dt, acct_id from (
-> select * from xyz_2007_01
-> union all
-> select * from xyz_2007_02
-> union all
-> select * from xyz_2007_03) t
-> where t.report_dt ='2007-02-17'
-> and t.acct_id = 'X0000741';
+----+--------------+--------------+------+---------------+------+---------+------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------+--------------+------+---------------+------+---------+------+---------+-------------+
| 1 | PRIMARY | derived2 | ALL | NULL | NULL | NULL | NULL | 3000000 | Using where |
| 2 | DERIVED | xyz_2007_01 | ALL | NULL | NULL | NULL | NULL | 788670 | |
| 3 | UNION | xyz_2007_02 | ALL | NULL | NULL | NULL | NULL | 1014751 | |
| 4 | UNION | xyz_2007_03 | ALL | NULL | NULL | NULL | NULL | 1096175 | |
|NULL | UNION RESULT | union2,3,4 | ALL | NULL | NULL | NULL | NULL | NULL | |
+----+--------------+--------------+------+---------------+------+---------+------+---------+-------------+
5 rows in set (35.51 sec)
Basically the same thing. Lets see what happens if I only get the fields I want in the sub-query.
mysql> explain select id, report_dt, acct_id from (
-> select id, report_dt, acct_id from xyz_2007_01
-> union all
-> select id, report_dt, acct_id from xyz_2007_02
-> union all
-> select id, report_dt, acct_id from xyz_2007_03) t
-> where report_dt = '2007-02-17'
-> and acct_id = 'X0000741';
+----+--------------+--------------+-------+---------------+----------------------+---------+------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------+--------------+-------+---------------+----------------------+---------+------+---------+-------------+
| 1 | PRIMARY | derived2 | ALL | NULL | NULL | NULL | NULL | 3000000 | Using where |
| 2 | DERIVED | xyz_2007_01 | index | NULL | xyz_rdt_acct_2007_01 | 15 | NULL | 788670 | Using index |
| 3 | UNION | xyz_2007_02 | index | NULL | xyz_rdt_acct_2007_02 | 15 | NULL | 1014751 | Using index |
| 4 | UNION | xyz_2007_03 | index | NULL | xyz_rdt_acct_2007_03 | 15 | NULL | 1096175 | Using index |
|NULL | UNION RESULT | union2,3,4 | ALL | NULL | NULL | NULL | NULL | NULL | |
+----+--------------+--------------+-------+---------------+----------------------+---------+------+---------+-------------+
5 rows in set (16.09 sec)
Well, look at that. 16 seconds still isn't great, but at least the query is using the indexes.
Lets create a view using the same logic.
mysql> drop view xyz;
Query OK, 0 rows affected (0.01 sec)
mysql> create view xyz as
-> select id, report_dt, acct_id from xyz_2007_01
-> union all
-> select id, report_dt, acct_id from xyz_2007_02
-> union all
-> select id, report_dt, acct_id from xyz_2007_03;
Query OK, 0 rows affected (0.00 sec)
mysql> select id, report_dt, acct_id from xyz where report_dt ='2007-02-17' and acct_id = 'X0000741';
+----------+------------+----------+
| id | report_dt | acct_id |
+----------+------------+----------+
| 20000741 | 2007-02-17 | X0000741 |
| 20967398 | 2007-02-17 | X0000741 |
+----------+------------+----------+
2 rows in set (16.70 sec)
Performance is consistent at least.
mysql> explain select id, report_dt, acct_id from xyz where report_dt ='2007-02-17' and acct_id = 'X0000741';
+----+--------------+--------------+-------+---------------+----------------------+---------+------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+--------------+--------------+-------+---------------+----------------------+---------+------+---------+-------------+
| 1 | PRIMARY | derived2 | ALL | NULL | NULL | NULL | NULL | 3000000 | Using where |
| 2 | DERIVED | xyz_2007_01 | index | NULL | xyz_rdt_acct_2007_01 | 15 | NULL | 788670 | Using index |
| 3 | UNION | xyz_2007_02 | index | NULL | xyz_rdt_acct_2007_02 | 15 | NULL | 1014751 | Using index |
| 4 | UNION | xyz_2007_03 | index | NULL | xyz_rdt_acct_2007_03 | 15 | NULL | 1096175 | Using index |
|NULL | UNION RESULT | union2,3,4 | ALL | NULL | NULL | NULL | NULL | NULL | |
+----+--------------+--------------+-------+---------------+----------------------+---------+------+---------+-------------+
5 rows in set (15.99 sec)
Plan is consistent as well. Still, not a solution for me, but thought you might be interested in the findings.
The more I learn, the more questions I have. Tomorrow, I test partitioning on 5.1 beta.
Wednesday, April 11, 2007
Why aren't there more of us?
I started reading Frank Hayes' piece on H-1Bs and Students last night with doubt because the two groups represent two different experience levels. Students are entry level workers and workers on H-1B visa's are typically experienced professionals. But those entry level workers eventually want to move on to experienced positions where they will compete on an uneven playing field with H-1B workers.
Now, it's no surprise that a view in Computerworld is slanted towards importing more workers. It's a genuine concern in our industry and therefore an appropriate subject to report on. Yet, they consistently fall on the side of the debate that advocates more H-1B workers.
Frank examines the trends of Computer Science graduates and correlates it to the rise and fall of the DotCom Boom and Bust. Personally, I dismiss those cycles because they just enticed people who weren't passionate about the profession and were chasing the almighty dollar. I think kids that want to get into this business because they think they will like it are scared. Scared they will be in a six-figure job with a mortgage and two kids when some C level executive decides to offshore the whole operation to China. Scared that they'll end up being 40 and be replaced by some guy willing to take 1/2 of what they make.
Where do these crazy kids get these ideas? The national media as well as several trade publications shout it from the rooftops daily. As someone who hires IT workers regularly, I can tell you that's not the case. I'll typically go through a couple dozen resumes to fill one spot. I have a spot that went unfilled because I just couldn't find someone to fill it. Maybe you won't spend 20 years at the same company, but the work is there if you want it.
I think there is a flaw in Mr. Hayes' numbers as well. While CS graduates are most likely destined for the IT industry, there are so many other disciplines that turn out IT workers. Hiring managers need to look beyond the engineering programs and open their search up to all the majors. Some of my best people have come from respected science or business programs.
I don't think it's all gloom and doom for the IT industry in this country. The press may lead you to think that everything is being outsourced to somewhere else, but the fact is there's a lot of work out there for the taking.
Now, it's no surprise that a view in Computerworld is slanted towards importing more workers. It's a genuine concern in our industry and therefore an appropriate subject to report on. Yet, they consistently fall on the side of the debate that advocates more H-1B workers.
Frank examines the trends of Computer Science graduates and correlates it to the rise and fall of the DotCom Boom and Bust. Personally, I dismiss those cycles because they just enticed people who weren't passionate about the profession and were chasing the almighty dollar. I think kids that want to get into this business because they think they will like it are scared. Scared they will be in a six-figure job with a mortgage and two kids when some C level executive decides to offshore the whole operation to China. Scared that they'll end up being 40 and be replaced by some guy willing to take 1/2 of what they make.
Where do these crazy kids get these ideas? The national media as well as several trade publications shout it from the rooftops daily. As someone who hires IT workers regularly, I can tell you that's not the case. I'll typically go through a couple dozen resumes to fill one spot. I have a spot that went unfilled because I just couldn't find someone to fill it. Maybe you won't spend 20 years at the same company, but the work is there if you want it.
I think there is a flaw in Mr. Hayes' numbers as well. While CS graduates are most likely destined for the IT industry, there are so many other disciplines that turn out IT workers. Hiring managers need to look beyond the engineering programs and open their search up to all the majors. Some of my best people have come from respected science or business programs.
I don't think it's all gloom and doom for the IT industry in this country. The press may lead you to think that everything is being outsourced to somewhere else, but the fact is there's a lot of work out there for the taking.
Wednesday, April 04, 2007
10gR2/9iR2 Distributed bugs
Our environment is highly distributed on a bunch of nodes partitioned out by business area. When a business area needs information from another business area, we create a Materialized View and pull the data across a database link. Most systems don't need up-to-the-minute data and when they do, there's other ways to get it.
Now, we're in a somewhat unique position because we're migrating Solaris 9iR2 dbs to Linux 10gR2. In fact, we just migrated one this weekend and experienced anywhere from 100% to 500% increase in performance depending on how much database work was actually being done. However, we did encounter some issues with db links that you might want to be aware of when migrating.
The master in this case was a 9.2.0.5 db on Solaris. We upgraded it to 10.2.0.3 and moved to Linux at the same time (good old export/import). There were several "client" dbs that ran the gamut across Oracle versions and OS Platforms.
The first problem was with 9.2.0.8/Solaris trying to get data from the 10.2.0.3/Linux db. We kept running into an error while trying to refresh the Mviews:
Here, the problem stems from bug 5671074. In this bug, 9.2.0.8 has a problem using dblinks when the "Endianess" doesn't match between sites. Also check out ML Note 415788.1. There is a one-off patch for the 9.2.0.8 software that needs to be applied and it worked fine for us.
The second issue was a little more straight forward, but unfathomable how it didn't get caught in testing. Here, we have two 10.2.0.3 dbs trying to use an unauthenticated database link (ie. no username/password hard-coded into the definition). An OS Authenticated user can connect to both dbs, but when he tries to access an object across a database link, he is presented with ORA-01017: invalid username/password. This functionality has worked since 8i and it escapes me how it slipped through the test cycle. This too resulted in a bug, but in 10.2. Check out bug 4624183 and ML Note 339238.1 for the current status. As of this post, the bug is fixed in 11.0 and has been backported to some platforms (not mine, of course). The only work around that worked for us was to use authenticated db links with the username/password embedded in the db link. Yuck.
Now, we're in a somewhat unique position because we're migrating Solaris 9iR2 dbs to Linux 10gR2. In fact, we just migrated one this weekend and experienced anywhere from 100% to 500% increase in performance depending on how much database work was actually being done. However, we did encounter some issues with db links that you might want to be aware of when migrating.
The master in this case was a 9.2.0.5 db on Solaris. We upgraded it to 10.2.0.3 and moved to Linux at the same time (good old export/import). There were several "client" dbs that ran the gamut across Oracle versions and OS Platforms.
The first problem was with 9.2.0.8/Solaris trying to get data from the 10.2.0.3/Linux db. We kept running into an error while trying to refresh the Mviews:
ERROR at line 1:
ORA-12008: error in materialized view refresh path
ORA-04052: error occurred when looking up remote object MYUSER.MVIEW_NAME@DBLINK_NAME
ORA-00604: error occurred at recursive SQL level 2
ORA-03106: fatal two-task communication protocol error
ORA-02063: preceding line from DBLINK_NAME
ORA-06512: at "SYS.DBMS_SNAPSHOT", line 820
ORA-06512: at "SYS.DBMS_SNAPSHOT", line 877
ORA-06512: at "SYS.DBMS_SNAPSHOT", line 858
Here, the problem stems from bug 5671074. In this bug, 9.2.0.8 has a problem using dblinks when the "Endianess" doesn't match between sites. Also check out ML Note 415788.1. There is a one-off patch for the 9.2.0.8 software that needs to be applied and it worked fine for us.
The second issue was a little more straight forward, but unfathomable how it didn't get caught in testing. Here, we have two 10.2.0.3 dbs trying to use an unauthenticated database link (ie. no username/password hard-coded into the definition). An OS Authenticated user can connect to both dbs, but when he tries to access an object across a database link, he is presented with ORA-01017: invalid username/password. This functionality has worked since 8i and it escapes me how it slipped through the test cycle. This too resulted in a bug, but in 10.2. Check out bug 4624183 and ML Note 339238.1 for the current status. As of this post, the bug is fixed in 11.0 and has been backported to some platforms (not mine, of course). The only work around that worked for us was to use authenticated db links with the username/password embedded in the db link. Yuck.
Sunday, April 01, 2007
My DST Nightmare
I had to be somewhere this morning at 9:00. It would take a little over an an hour to get there, so I figured I better leave by 7:30 just to be safe. That meant setting the alarm clock to 6:45.
6:45 came and the alarm went off as expected. I jumped into the shower, got dressed, and as I was heading out the door my wife says "Where are you going so early?" I told her and she rolled back over and went back to sleep.
Then I jumped into a car I usually don't drive. "Hmm, the clock says 6:32", I thought to myself, "must be I haven't driven this car for three weeks."
I reset the clock to the correct time and was off.
I got to my destination at 8:50 and there were only a couple people there. I was expecting about 60 or 70!
I approached the guy in charge and said "I must have read they flyer wrong..."
"Oh, that's today, but starts at 9:00" he says.
I looked at my phone and it said 7:50. 7:50, WTF?
Ah, yes, Daylight Savings Time. Not the "new" Daylight Savings Time, but the "old" Daylight Savings Time.
I have one of those "fancy" clocks that automatically adjusts for Daylight Savings Time. Except, I got it a couple years ago and it still thinks that the first Sunday in April is the right time to "spring forward".
Sure enough, I got home and my clock was an hour ahead of everything else. I promptly went back down to the car and reset the clock. Interestingly enough, my W2K box that was supposed to be patched with all the latest updates was also an hour ahead.
6:45 came and the alarm went off as expected. I jumped into the shower, got dressed, and as I was heading out the door my wife says "Where are you going so early?" I told her and she rolled back over and went back to sleep.
Then I jumped into a car I usually don't drive. "Hmm, the clock says 6:32", I thought to myself, "must be I haven't driven this car for three weeks."
I reset the clock to the correct time and was off.
I got to my destination at 8:50 and there were only a couple people there. I was expecting about 60 or 70!
I approached the guy in charge and said "I must have read they flyer wrong..."
"Oh, that's today, but starts at 9:00" he says.
I looked at my phone and it said 7:50. 7:50, WTF?
Ah, yes, Daylight Savings Time. Not the "new" Daylight Savings Time, but the "old" Daylight Savings Time.
I have one of those "fancy" clocks that automatically adjusts for Daylight Savings Time. Except, I got it a couple years ago and it still thinks that the first Sunday in April is the right time to "spring forward".
Sure enough, I got home and my clock was an hour ahead of everything else. I promptly went back down to the car and reset the clock. Interestingly enough, my W2K box that was supposed to be patched with all the latest updates was also an hour ahead.
Friday, March 30, 2007
The final nail for shared servers
I've been running shared servers and dedicated servers in a mixed mode for a number of years. In theory, there are a lot of advantages to shared servers; connection pooling, connection multiplexing, and pre-established connections.
I like to setup one database alias for dedicated connections (middle-tiers, batch jobs, etc.) and one for shared connections (CGI scripts, mod_plsql, and Client/Server sessions that have a lot of "think" time). Each alias then points to a specific listener that is either setup as a local listener or is a dispatcher. Granted, tracing is never easy on a session that is connected to a shared server. But, in general, it worked pretty good.
About a year ago I had a problem where my multiplexed connections periodically got disconnected. We tracked it down to an issue with multiplexing (implemented in shared servers) on 9.2 and Linux. For this particular application, shared servers weren't critical, so we just rerouted the alias to a dedicated listener.
Over the past 6 months or so, we've been experiencing in-memory block corruption in 9.2 dbs on 64-bit Linux. It was on multiple hosts, multiple dbs, and different patch levels of Oracle. Since the problem wasn't consistent and disguised itself as multiple ORA-00600/07445 errors we, nor Oracle Support, could ever track the root cause. Time would go by without error, the TAR would get closed, and we would experience a different ORA-00600 error.
After much prodding, we finally got an analyst at Oracle that understood what we were up against and looked at ALL our TARs, not just the current problem. They pieced together everything and pointed to bug 5324905; memory corruption from shared servers.
While they are great in theory, the disadvantages of shared servers outweigh the advantages at this point.
I like to setup one database alias for dedicated connections (middle-tiers, batch jobs, etc.) and one for shared connections (CGI scripts, mod_plsql, and Client/Server sessions that have a lot of "think" time). Each alias then points to a specific listener that is either setup as a local listener or is a dispatcher. Granted, tracing is never easy on a session that is connected to a shared server. But, in general, it worked pretty good.
About a year ago I had a problem where my multiplexed connections periodically got disconnected. We tracked it down to an issue with multiplexing (implemented in shared servers) on 9.2 and Linux. For this particular application, shared servers weren't critical, so we just rerouted the alias to a dedicated listener.
Over the past 6 months or so, we've been experiencing in-memory block corruption in 9.2 dbs on 64-bit Linux. It was on multiple hosts, multiple dbs, and different patch levels of Oracle. Since the problem wasn't consistent and disguised itself as multiple ORA-00600/07445 errors we, nor Oracle Support, could ever track the root cause. Time would go by without error, the TAR would get closed, and we would experience a different ORA-00600 error.
After much prodding, we finally got an analyst at Oracle that understood what we were up against and looked at ALL our TARs, not just the current problem. They pieced together everything and pointed to bug 5324905; memory corruption from shared servers.
While they are great in theory, the disadvantages of shared servers outweigh the advantages at this point.
Thursday, March 22, 2007
The beauty of having your business logic in the database...
You may recall that I banged together a small application using Apex (nee HTMLDB) a few months ago. I got a call from a user the other day that something wasn't working quite right. Seems as one of the pages was giving them an incorrect result. I hadn't touched this particular application in about 2 months, but I knew it pulled information from a view I created just to make the Apex interface easy. The view called a piece of PL/SQL code that calculated a particular metric on-the-fly and due to some business rules, that calculation changed. It was a business-wide change, so I consulted the parties that use this package and we all agreed on the change to be made. I made the change and everybody was happy. I didn't have to get back into Apex or anything, just a simple PL/SQL change and I was done.
For those people that thought they had a better idea and rewrote the business logic in their Java middle-tier, good luck.
For those people that thought they had a better idea and rewrote the business logic in their Java middle-tier, good luck.
Tuesday, March 20, 2007
Monday, March 12, 2007
ORA-01009 During Gap Resolution
Encountered an interesting error with an Oracle 10.2.0.3 physical standby database.
When the standby database encounters a gap in the archivelog sequence, it tries to resolve the gap but encounters an ORA-01009: missing mandatory parameter. The interesting thing is that the standby eventually resolves the gap and gets caught up.
At first, my DB's are in sync. The standby db is applying logs as they come in without issue:
Then, a gap is artificially generated by deferring log_archive_dest_2 log shipping at log 2045. When log shipping is enabled again, my standby recognizes the gap, but generates the ORA-01009 error.
Somehow, though, the gap is resolved and the logs are applied.
The mrp0.trc file doesn't give me very many clues either:
At first I thought this might be NLS related, but both primary and standby hosts are configured similarly. The oerr tends to indicate some OCI/Precompiler issue, but I would think Oracle knows how to use their own libraries. Still trying to figure this one out...
When the standby database encounters a gap in the archivelog sequence, it tries to resolve the gap but encounters an ORA-01009: missing mandatory parameter. The interesting thing is that the standby eventually resolves the gap and gets caught up.
At first, my DB's are in sync. The standby db is applying logs as they come in without issue:
Completed: ALTER DATABASE RECOVER managed standby database disconnect
Fri Mar 9 15:27:59 2007
Redo Shipping Client Connected as PUBLIC
-- Connected User is Valid
RFS[1]: Assigned to RFS process 17076
RFS[1]: Identified database type as 'physical standby'
Fri Mar 9 15:27:59 2007
RFS LogMiner: Client disabled from further notification
RFS[1]: No standby redo logfiles created
RFS[1]: Archived Log: '/u01/oraarch/db1/1_2043_612798267.dbf'
Fri Mar 9 15:28:08 2007
Media Recovery Log /u01/oraarch/db1/1_2043_612798267.dbf
Media Recovery Waiting for thread 1 sequence 2044
Fri Mar 9 15:28:14 2007
RFS[1]: No standby redo logfiles created
RFS[1]: Archived Log: '/u01/oraarch/db1/1_2044_612798267.dbf'
Fri Mar 9 15:28:22 2007
Media Recovery Log /u01/oraarch/db1/1_2044_612798267.dbf
Media Recovery Waiting for thread 1 sequence 2045
Then, a gap is artificially generated by deferring log_archive_dest_2 log shipping at log 2045. When log shipping is enabled again, my standby recognizes the gap, but generates the ORA-01009 error.
Media Recovery Waiting for thread 1 sequence 2045
Fetching gap sequence in thread 1, gap sequence 2045-2045
FAL[client, MRP0]: Error 1009 fetching archived redo log from db1.us
Fri Mar 9 15:28:29 2007
Errors in file /oracle/app/oracle/admin/db1/bdump/db1_mrp0_16203.trc:
ORA-01009: missing mandatory parameter
Fri Mar 9 15:28:30 2007
Somehow, though, the gap is resolved and the logs are applied.
RFS[1]: No standby redo logfiles created
RFS[1]: Archived Log: '/u01/oraarch/db1/1_2045_612798267.dbf'
Fri Mar 9 15:28:43 2007
The mrp0.trc file doesn't give me very many clues either:
/oracle/app/oracle/admin/db1/bdump/db1_mrp0_16203.trc
Oracle Database 10g Enterprise Edition Release 10.2.0.3.0 - Production
With the Partitioning and Data Mining options
ORACLE_HOME = /oracle/app/oracle/product/10.2.0.3
System name: Linux
Node name: dev101
Release: 2.6.9-42.0.3.EL
Version: #1 Mon Sep 25 17:14:19 EDT 2006
Machine: i686
Instance name: db1
Redo thread mounted by this instance: 1
Oracle process number: 18
Unix process pid: 16203, image: oracle@dev101 (MRP0)
*** SERVICE NAME:() 2007-03-09 15:26:53.586
*** SESSION ID:(153.1) 2007-03-09 15:26:53.586
ARCH: Connecting to console port...
*** 2007-03-09 15:26:53.586 61283 kcrr.c
MRP0: Background Managed Standby Recovery process started
*** 2007-03-09 15:26:58.586 1102 krsm.c
Managed Recovery: Initialization posted.
*** 2007-03-09 15:26:58.586 61283 kcrr.c
Managed Standby Recovery not using Real Time Apply
Recovery target incarnation = 1, activation ID = 207497211
Influx buffer limit = 2245 (50% x 4491)
Successfully allocated 2 recovery slaves
Using 543 overflow buffers per recovery slave
Start recovery at thread 1 ckpt scn 39582826471 logseq 2043 block 2
*** 2007-03-09 15:26:58.663
Media Recovery add redo thread 1
*** 2007-03-09 15:26:58.663 1102 krsm.c
Managed Recovery: Active posted.
*** 2007-03-09 15:26:58.930 61283 kcrr.c
Media Recovery Waiting for thread 1 sequence 2043
*** 2007-03-09 15:28:08.945
Media Recovery Log /u01/oraarch/db1/1_2043_612798267.dbf
*** 2007-03-09 15:28:12.150 61283 kcrr.c
Media Recovery Waiting for thread 1 sequence 2044
*** 2007-03-09 15:28:22.151
Media Recovery Log /u01/oraarch/db1/1_2044_612798267.dbf
*** 2007-03-09 15:28:24.353 61283 kcrr.c
Media Recovery Waiting for thread 1 sequence 2045
*** 2007-03-09 15:28:29.353 61283 kcrr.c
Fetching gap sequence in thread 1, gap sequence 2045-2045
*** 2007-03-09 15:28:29.470 61283 kcrr.c
FAL[client, MRP0]: Error 1009 fetching archived redo log from db1.us
ORA-01009: missing mandatory parameter
*** 2007-03-09 15:28:59.471
Media Recovery Log /u01/oraarch/db1/1_2045_612798267.db
At first I thought this might be NLS related, but both primary and standby hosts are configured similarly. The oerr tends to indicate some OCI/Precompiler issue, but I would think Oracle knows how to use their own libraries. Still trying to figure this one out...
Tuesday, March 06, 2007
Targeted Marketing
You know those coupons you get at the end of your register receipt at the grocery store? You know the kind, you buy Charmin and they give you $.25 of Scotts. I went to CVS the other day to pickup a bag of M&Ms for an afternoon snack. I check the bottom of the coupon since occasionally they'll give you a $.50 off your next purchase. What was on the bottom but a coupon for $1.00 of my next purchase of Playtex Tampons. Methinks somebody needs to tune their Datawarehouse...
Monday, March 05, 2007
If it's good enough for the DOT...
Make no mistake about it, I'm not running out to "upgrade" to Windoz anything as long as my heart is pumping. However, if you're stuck in a Windoz environment, here's a unique take on Windows Vista upgrades; just don't do it.
On a side note, I can see six network administrators standing over a PC with one PC-Tech replacing the hard drive at the DOT. Or maybe that's just stereotypical....
On a side note, I can see six network administrators standing over a PC with one PC-Tech replacing the hard drive at the DOT. Or maybe that's just stereotypical....
Sunday, March 04, 2007
Oracle's January CPU update
Hi all!
Thought I'd share a potential problem solver for the latest Jan CPU patch for Oracle. If you're running Solaris 10, the patch could possibly fail because Solaris 10 adds "a few bytes"to the size of the objects and opatch bombs during the validation phase.
Two ways to solve this... upgrade your opatch version to 1.0.0.0.56 (or better) or Set the environment variable OPATCH_SKIP_VERIFY=TRUE before you start. Personally I'd opt to go get the latest version of OPatch Patch 4898608 (considering Oracle just updated it 14-feb-2007)
Check out note:397342.1 for further details.
Yeah, I know it's March already I don't want to hear it...
Thought I'd share a potential problem solver for the latest Jan CPU patch for Oracle. If you're running Solaris 10, the patch could possibly fail because Solaris 10 adds "a few bytes"to the size of the objects and opatch bombs during the validation phase.
Two ways to solve this... upgrade your opatch version to 1.0.0.0.56 (or better) or Set the environment variable OPATCH_SKIP_VERIFY=TRUE before you start. Personally I'd opt to go get the latest version of OPatch Patch 4898608 (considering Oracle just updated it 14-feb-2007)
Check out note:397342.1 for further details.
Yeah, I know it's March already I don't want to hear it...
Wednesday, February 21, 2007
Thursday, February 15, 2007
Dead Air
Sorry for the dead air recently. When I'm on a database project, I'll post regularly on things I find or other tidbits of information I encounter during the project. Even when I'm working on a MySQL project, I'll usually have something to say about what's going on or what I'm learning.
But lately, I've been on an Oracle Applications project. There's two reasons I don't like to talk about Oracle Applications projects. First, it's strategic to the company and I don't really want to blog about company specific things. Second, I hate dealing with it. The patches are unbelievable, the processes on Metalink rarely work out of the box, and the product is so overly complex that it's extremely difficult to administer. It's just a very laborious process that I dread every time I start something new. And there's really nothing exciting about it. Except the day after I upgraded to 11.5.9, 11.5.10 came out.
So stick with me. Next up is some MySQL stuff and hopefully some 10g findings.
But lately, I've been on an Oracle Applications project. There's two reasons I don't like to talk about Oracle Applications projects. First, it's strategic to the company and I don't really want to blog about company specific things. Second, I hate dealing with it. The patches are unbelievable, the processes on Metalink rarely work out of the box, and the product is so overly complex that it's extremely difficult to administer. It's just a very laborious process that I dread every time I start something new. And there's really nothing exciting about it. Except the day after I upgraded to 11.5.9, 11.5.10 came out.
So stick with me. Next up is some MySQL stuff and hopefully some 10g findings.
Tuesday, February 06, 2007
10195 event, epilogue
You may recall my recent issues with Oracle and predicate generation, here, here, here, and here.
We set the 10195 event for the entire instance in once case to see if it would fix our general problem without breaking everything else. Alas, the 10195 event stopped generating predicates, but changed execution plans on other queries as well. We confirmed this by turning the 10195 event off at the session level and re-executing (and reparsing) the query. As a general observation, the 10195 had a tendency to favor hash joins over everything else. Now we get to decide what is more important; performance or data integrity.
We set the 10195 event for the entire instance in once case to see if it would fix our general problem without breaking everything else. Alas, the 10195 event stopped generating predicates, but changed execution plans on other queries as well. We confirmed this by turning the 10195 event off at the session level and re-executing (and reparsing) the query. As a general observation, the 10195 had a tendency to favor hash joins over everything else. Now we get to decide what is more important; performance or data integrity.
Monday, February 05, 2007
Upgrading to 10.2.0.3
Be advised that if you're upgrading to 64-bit 10.2.0.3 from a database that was ever a 32-bit db, you should read Metalink Note 412271.1. Otherwise, you'll be hit with:
And yes, OracleDoc, this was in test.
ORA-00600: internal error code, arguments: [22635], [], [], [], [], [], [], []
ORA-06512: at "SYS.UPGRADE_SYSTEM_TYPES_FROM_920", line1
And yes, OracleDoc, this was in test.
Tuesday, January 30, 2007
If it could all possibly go wrong...
If it could all possibly go wrong... it did.
I upgraded one of my databases from 9.2.0.7 to 10.2.0.2 this past weekend. What normally should have taken about 2 hours took 9. Everything that could have possibly gone wrong with an upgrade did, and I’m just glad that I was able to finally get it done and open for business without having to recover it and go back to the drawing board. For those of you who are still in the 9i world and are going to be upgrading here in the future please for God’s sake bookmark this blog entry or the Metalink notes provided. Maybe it will save you, maybe it wont….
It all started by using the DBUA. I was directed to use this wonderful and fantastic tool instead of manually doing it. Someone thinks watching a progress bar is much cooler than watching code go flying by.
According to the DBUA and associated logs after the upgrade everything was just dandy! I shut the database down poked around a bit giving myself a peace of mind then fired it backup.
BAM!
ORA-00604: error occurred at recursive SQL levelError 604 happened during db open, shutting down database
USER: terminating instance due to error 604Instance terminated by USER, pid = 13418
ORA-1092 signalled during: ALTER DATABASE OPEN
I spent the next 30 minutes trying everything I could think of as well as scouring Metalink for some kind of clue as to what was causing this. I came up with Nada, zip, nothing! I had to break down and open up a case with Oracle. After sending them all the logs and explanations, they came back with “go run the catupgrd.sql” script and see if it fixes it. Why, I have no clue but it fixed the problem and I was able to open the database.
Database is open all looks well, ok time to enable the database jobs (mainly my stats pack job).
BAM!
ORA-12899: value too large for column "PERFSTAT"."STATS$SGASTAT"."POOL"(actual: 12, maximum: 11)
ORA-06512: at "PERFSTAT.STATSPACK", line 2065ORA-06512: at PERFSTAT.STATSPACK", line 91ORA-06512: at line 1
WARNING: Detected too many memory locking problems.WARNING: Performance degradation may occur.
I figured the easy fix for this one was to simply go in and blow away perfstat and recreate him again. New database, new stats hmmm why not? Confirmed with Oracle since I still had the case open with them and they confirmed that that was the best course of action as well. $ORACLE_HOME/rdbms/admin/spdrop.sql $ORACLE_HOME/rdbms/admin/spcreate.sql easy enough.
Ok, Database is up Perfstat is fixed no errors in the alertlog, jobs are enabled, alright lets go ahead start the listener and let some feeds come in.
BAM!
ORA-04065: not executed, altered or dropped stored procedure"PUBLIC.DBMS_OUTPUT"ORA-06508: PL/SQL: could not find program unit being called:"PUBLIC.DBMS_OUTPUT"
Ohhh this is a good one. Apparently according to Metalink this error occurs because this package got its memory status broken at some point in time. When the package is recompiled, this status is cleared but (big but) the situation can still occur. The way to fix this issue is to run the utlirp.sql (not to be confused with the utlrp.sql) Check out Metalink note 370137.1 and it will explain it all.
Alright, utlirp.sql has been ran database got bounced (again) everything is looking good, feeds look good. Everything is satisfactory let’s back this puppy up.
BAM!
RMAN-03009: failure of backup command on ORA_DISK_3 channel
RMAN-10038: database session for channel ORA_DISK_3 terminated unexpectedly
channel ORA_DISK_3 disabled, job failed on it will be run on another channel
ORA-07445: exception encountered: core dump [memcpy()+40] [SIGSEGV] [Address not mapped to object] [0x000000000] [] []
This is caused because the Controlfile autobackup parameter is off in the RMAN configuration. A nifty little bug, Check out note 399395.1 for details.
The parameter is in the “on” position… back the database up……. Good backup.! Let’s open her up for business!!
Next morning I come in check the alert log ok, ok, good, uhh huuu,…
BAM!
ORA-00054: resource busy and acquire with NOWAIT specified
ORA-06512: at "SYS.DBMS_STATS", line 13313
ORA-06512: at "SYS.DBMS_STATS", line 13659
ORA-06512: at "SYS.DBMS_STATS", line 13737
ORA-06512: at "SYS.DBMS_STATS", line 13696
ORA-06512: at "SYSTEM.DB_SCHEMA_STATS", line 7
ORA-06512: at line 1
Another bug only thing is I’m kind of confused because the note says 10.2.0.1.0 and we went to 10.2.0.2. Also it says the only way to analyze the object(s) in question is to do it during next scheduled maintenance or gather the stats before any refresh operation. Uhh sorry to tell you guys but I need to run stats at least twice a week with the amount of transactions I’m doing, and my refresh job runs like every 5 minutes. Got to think of an alternative. Note:377183.1
I’m done..think I’m going to go and take my aggressions out and play some World of Warcraft.
I upgraded one of my databases from 9.2.0.7 to 10.2.0.2 this past weekend. What normally should have taken about 2 hours took 9. Everything that could have possibly gone wrong with an upgrade did, and I’m just glad that I was able to finally get it done and open for business without having to recover it and go back to the drawing board. For those of you who are still in the 9i world and are going to be upgrading here in the future please for God’s sake bookmark this blog entry or the Metalink notes provided. Maybe it will save you, maybe it wont….
It all started by using the DBUA. I was directed to use this wonderful and fantastic tool instead of manually doing it. Someone thinks watching a progress bar is much cooler than watching code go flying by.
According to the DBUA and associated logs after the upgrade everything was just dandy! I shut the database down poked around a bit giving myself a peace of mind then fired it backup.
BAM!
ORA-00604: error occurred at recursive SQL levelError 604 happened during db open, shutting down database
USER: terminating instance due to error 604Instance terminated by USER, pid = 13418
ORA-1092 signalled during: ALTER DATABASE OPEN
I spent the next 30 minutes trying everything I could think of as well as scouring Metalink for some kind of clue as to what was causing this. I came up with Nada, zip, nothing! I had to break down and open up a case with Oracle. After sending them all the logs and explanations, they came back with “go run the catupgrd.sql” script and see if it fixes it. Why, I have no clue but it fixed the problem and I was able to open the database.
Database is open all looks well, ok time to enable the database jobs (mainly my stats pack job).
BAM!
ORA-12899: value too large for column "PERFSTAT"."STATS$SGASTAT"."POOL"(actual: 12, maximum: 11)
ORA-06512: at "PERFSTAT.STATSPACK", line 2065ORA-06512: at PERFSTAT.STATSPACK", line 91ORA-06512: at line 1
WARNING: Detected too many memory locking problems.WARNING: Performance degradation may occur.
I figured the easy fix for this one was to simply go in and blow away perfstat and recreate him again. New database, new stats hmmm why not? Confirmed with Oracle since I still had the case open with them and they confirmed that that was the best course of action as well. $ORACLE_HOME/rdbms/admin/spdrop.sql $ORACLE_HOME/rdbms/admin/spcreate.sql easy enough.
Ok, Database is up Perfstat is fixed no errors in the alertlog, jobs are enabled, alright lets go ahead start the listener and let some feeds come in.
BAM!
ORA-04065: not executed, altered or dropped stored procedure"PUBLIC.DBMS_OUTPUT"ORA-06508: PL/SQL: could not find program unit being called:"PUBLIC.DBMS_OUTPUT"
Ohhh this is a good one. Apparently according to Metalink this error occurs because this package got its memory status broken at some point in time. When the package is recompiled, this status is cleared but (big but) the situation can still occur. The way to fix this issue is to run the utlirp.sql (not to be confused with the utlrp.sql) Check out Metalink note 370137.1 and it will explain it all.
Alright, utlirp.sql has been ran database got bounced (again) everything is looking good, feeds look good. Everything is satisfactory let’s back this puppy up.
BAM!
RMAN-03009: failure of backup command on ORA_DISK_3 channel
RMAN-10038: database session for channel ORA_DISK_3 terminated unexpectedly
channel ORA_DISK_3 disabled, job failed on it will be run on another channel
ORA-07445: exception encountered: core dump [memcpy()+40] [SIGSEGV] [Address not mapped to object] [0x000000000] [] []
This is caused because the Controlfile autobackup parameter is off in the RMAN configuration. A nifty little bug, Check out note 399395.1 for details.
The parameter is in the “on” position… back the database up……. Good backup.! Let’s open her up for business!!
Next morning I come in check the alert log ok, ok, good, uhh huuu,…
BAM!
ORA-00054: resource busy and acquire with NOWAIT specified
ORA-06512: at "SYS.DBMS_STATS", line 13313
ORA-06512: at "SYS.DBMS_STATS", line 13659
ORA-06512: at "SYS.DBMS_STATS", line 13737
ORA-06512: at "SYS.DBMS_STATS", line 13696
ORA-06512: at "SYSTEM.DB_SCHEMA_STATS", line 7
ORA-06512: at line 1
Another bug only thing is I’m kind of confused because the note says 10.2.0.1.0 and we went to 10.2.0.2. Also it says the only way to analyze the object(s) in question is to do it during next scheduled maintenance or gather the stats before any refresh operation. Uhh sorry to tell you guys but I need to run stats at least twice a week with the amount of transactions I’m doing, and my refresh job runs like every 5 minutes. Got to think of an alternative. Note:377183.1
I’m done..think I’m going to go and take my aggressions out and play some World of Warcraft.
Y2K All over again
Does anybody else feel like it's 1999 again with all these DST fixes that have to go in?
Tuesday, January 23, 2007
dizwell.com
I can always tell when HJR changes something on dizwell.com. This time I broke the record and got five copies of every post for the last two weeks through the RSS feed. During October "upgrade" I only got three. Looks like things have calmed down, down under.
Powered by Zoundry
Friday, January 19, 2007
Cookbooks
I'm a big fan of what I call cookbooks. Cookbooks are step-by-step directions that if followed, will yield the desired result. In fact, most of my cookbooks are copy & past enabled so that you copy a command from the cookbook and paste it into your window to execute the command. I insist my people use these established methods where available and I get pretty ticked off when they waste a lot of time trying to figure out what has already been learned.
I've installed Oracle on Linux about 50 times over the past few months. After the second succesfull install, I created a cookbook for both 9i and 10g. If followed exactly, any DBA will be able to install Oracle correctly in my environment. I created the cookbook and I know it like the back of my hand. I don't need no stinkin cookbook and proceeded to do a fresh install of 9.2.0.8 when the installer hangs at 18% linking naeet.o.
"Hmm, must be somthing wrong with Linux", I thought to myself.
I checked that the correct versions of gcc and g++ were in my path. I knew I set LD_ASSUME_KERNEL so I didn't have to check that. Then I looked at metlink and found a note that said my LD_ASSUME_KERNEL had to be 2.4.19, which I already knew I set, so that couldn't be it.
I poked around at some other things before going back to my cookbook.
Kernel parameters, check.
ORACLE_HOME set, check.
LD_ASSUME_KERNEL, I know I set that, skip it.
Correct version of gcc and g++, check.
Reran the installer and it hung again at 18%.
The only thing I didn't double check was LD_ASSUME_KERNEL. So I see what's in the environment variable, and lo and behold, it's not set. Seems I set LD_ASSUMEKERNEL instead of LD_ASSUME_KERNEL.
I've sent a stern email to myself about not following process. If I do it again, I'll be fired.
Powered by Zoundry
Friday, January 12, 2007
Jonathan Lewis is one smart dude
First, let me say that Jonathan Lewis has helped me immensely on my optimizer problem (here, here, and here). Without his help, I'd still be banging my head against a brick wall and arguing with Oracle Support as to why I need to upgrade to 10.2.0.3. A hundred thank you's, Jonathan. (I hope this doesn't land me on the "dummy list" of the next Scratchpad post)
Back to my optimizer issue, I should have known the plan was cached.
Let me take that back, I knew the plan was cached, but assumed (I know, I know) that the 10195 event would require a hard parse again. In retrospect, that was a silly thought, but seemed logical in the heat of battle. Anyway, the 10195 event does indeed turn off predicate generation for check constraints. Updated script and results to follow.
It still begs the question as to why Oracle evaluates the constraints this way (other than the response I got from Oracle Support "that's the way it works"), but at least we have a way out now.
Script:
Results:
Back to my optimizer issue, I should have known the plan was cached.
Let me take that back, I knew the plan was cached, but assumed (I know, I know) that the 10195 event would require a hard parse again. In retrospect, that was a silly thought, but seemed logical in the heat of battle. Anyway, the 10195 event does indeed turn off predicate generation for check constraints. Updated script and results to follow.
It still begs the question as to why Oracle evaluates the constraints this way (other than the response I got from Oracle Support "that's the way it works"), but at least we have a way out now.
Script:
set timing on
set echo on;
alter system flush shared_pool;
drop table t1;
create table t1 (
id number primary key,
date_matched date,
other_stuff varchar2(222),
constraint ck1 check (date_matched = trunc(date_matched))
);
drop table t2;
create table t2 (
id number primary key,
date_matched date,
other_stuff varchar2(222)
);
declare
dm date;
dc integer := 0;
begin
for i in 1..100000 loop
if mod(i,10) = 0 then
dm := trunc(sysdate + mod(dc,66));
dc := dc+1;
else
dm := to_date('12/31/4712','mm/dd/yyyy');
end if;
insert into t1 values (i, dm, rpad('x',mod(i,222)));
insert into t2 values (i, dm, rpad('x',mod(i,222)));
end loop;
commit;
dbms_stats.gather_table_stats(
ownname=>USER,
tabname=>'T1',
cascade=>true,
estimate_percent=>NULL);
dbms_stats.gather_table_stats(
ownname=>USER,
tabname=>'T2',
cascade=>true,
estimate_percent=>NULL);
end;
/
create index t1_dm on t1(date_matched);
create index t2_dm on t2(date_matched);
select * from v$version;
-- here's the explain plan before 10195 event
explain plan for select count(*) from t1 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
select * from table(dbms_xplan.display);
explain plan for select count(*) from t2 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
select * from table(dbms_xplan.display);
alter session set events '10195 trace name context forever, level 1';
-- here's the explain plan after
explain plan for select count(*) from t1 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
select * from table(dbms_xplan.display);
explain plan for select count(*) from t2 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
select * from table(dbms_xplan.display);
-- set the 10195 event off for now
alter session set events '10195 trace name context off';
-- lets get some blocks in cache
select count(*) from t1 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
select count(*) from t2 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
-- lets time one with tkprof
alter session set tracefile_identifier = 't1t2';
alter session set events '10046 trace name context forever, level 12';
-- add a comment to get a new plan
select /* 10195 OFF Q1 */ count(*) from t1 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
select /* 10195 OFF Q2 */ count(*) from t2 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
select /*+ rule 10195 OFF Q3 */ count(*) from t1 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
-- set 10195 event on again
alter session set events '10195 trace name context forever, level 1';
-- do queries again with new comments
select /* 10195 ON Q1 */ count(*) from t1 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
select /* 10195 ON Q2 */ count(*) from t2 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
select /*+ rule 10195 ON Q3 */ count(*) from t1 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
-- just for kicks, do the bad plan again
alter session set events '10195 trace name context off';
select /* 10195 OFF_AGAIN Q2 */ count(*) from t2 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
select /*+ rule 10195 OFF_AGAIN Q3 */ count(*) from t1 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
select /* 10195 OFF_AGAIN Q1 */ count(*) from t1 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
Results:
SQL> alter system flush shared_pool;
System altered.
Elapsed: 00:00:00.18
SQL> drop table t1;
Table dropped.
Elapsed: 00:00:00.97
SQL> create table t1 (
2 id number primary key,
3 date_matched date,
4 other_stuff varchar2(222),
5 constraint ck1 check (date_matched = trunc(date_matched))
6 );
Table created.
Elapsed: 00:00:00.06
SQL> drop table t2;
Table dropped.
Elapsed: 00:00:00.05
SQL> create table t2 (
2 id number primary key,
3 date_matched date,
4 other_stuff varchar2(222)
5 );
Table created.
Elapsed: 00:00:00.03
SQL> declare
2 dm date;
3 dc integer := 0;
4 begin
5 for i in 1..100000 loop
6 if mod(i,10) = 0 then
7 dm := trunc(sysdate + mod(dc,66));
8 dc := dc+1;
9 else
10 dm := to_date('12/31/4712','mm/dd/yyyy');
11 end if;
12 insert into t1 values (i, dm, rpad('x',mod(i,222)));
13 insert into t2 values (i, dm, rpad('x',mod(i,222)));
14 end loop;
15 commit;
16 dbms_stats.gather_table_stats(
17 ownname=>USER,
18 tabname=>'T1',
19 cascade=>true,
20 estimate_percent=>NULL);
21 dbms_stats.gather_table_stats(
22 ownname=>USER,
23 tabname=>'T2',
24 cascade=>true,
25 estimate_percent=>NULL);
26 end;
27 /
PL/SQL procedure successfully completed.
Elapsed: 00:00:36.07
SQL> create index t1_dm on t1(date_matched);
Index created.
Elapsed: 00:00:00.34
SQL> create index t2_dm on t2(date_matched);
Index created.
Elapsed: 00:00:00.34
SQL>
SQL> select * from v$version;
BANNER
----------------------------------------------------------------
Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Prod
PL/SQL Release 10.2.0.1.0 - Production
CORE 10.2.0.1.0 Production
TNS for Linux: Version 10.2.0.1.0 - Production
NLSRTL Version 10.2.0.1.0 - Production
Elapsed: 00:00:00.05
SQL>
SQL> -- here's the explain plan before 10195 event
SQL> explain plan for select count(*) from t1 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
Explained.
Elapsed: 00:00:00.03
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 1573756541
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 8 | 4 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 8 | | |
|* 2 | INDEX RANGE SCAN| T1_DM | 15 | 120 | 4 (0)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
---------------------------------------------------
2 - access("DATE_MATCHED"=TO_DATE('4712-12-31 00:00:00', 'yyyy-mm-dd
hh24:mi:ss'))
filter(TRUNC(INTERNAL_FUNCTION("DATE_MATCHED"))=TO_DATE('4712-12-
31 00:00:00', 'yyyy-mm-dd hh24:mi:ss'))
17 rows selected.
Elapsed: 00:00:00.15
SQL> explain plan for select count(*) from t2 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
Explained.
Elapsed: 00:00:00.01
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 3430539338
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 8 | 4 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 8 | | |
|* 2 | INDEX RANGE SCAN| T2_DM | 1493 | 11944 | 4 (0)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
---------------------------------------------------
2 - access("DATE_MATCHED"=TO_DATE('4712-12-31 00:00:00', 'yyyy-mm-dd
hh24:mi:ss'))
15 rows selected.
Elapsed: 00:00:00.02
SQL>
SQL> alter session set events '10195 trace name context forever, level 1';
Session altered.
Elapsed: 00:00:00.00
SQL>
SQL> -- here's the explain plan after
SQL> explain plan for select count(*) from t1 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
Explained.
Elapsed: 00:00:00.00
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 1573756541
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 8 | 4 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 8 | | |
|* 2 | INDEX RANGE SCAN| T1_DM | 1493 | 11944 | 4 (0)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
---------------------------------------------------
2 - access("DATE_MATCHED"=TO_DATE('4712-12-31 00:00:00', 'yyyy-mm-dd
hh24:mi:ss'))
15 rows selected.
Elapsed: 00:00:00.02
SQL> explain plan for select count(*) from t2 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
Explained.
Elapsed: 00:00:00.00
SQL> select * from table(dbms_xplan.display);
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 3430539338
---------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 8 | 4 (0)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | 8 | | |
|* 2 | INDEX RANGE SCAN| T2_DM | 1493 | 11944 | 4 (0)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
---------------------------------------------------
2 - access("DATE_MATCHED"=TO_DATE('4712-12-31 00:00:00', 'yyyy-mm-dd
hh24:mi:ss'))
15 rows selected.
Elapsed: 00:00:00.01
SQL>
SQL> -- set the 10195 event off for now
SQL> alter session set events '10195 trace name context off';
Session altered.
Elapsed: 00:00:00.00
SQL>
SQL> -- lets get some blocks in cache
SQL> select count(*) from t1 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
COUNT(*)
----------
90000
Elapsed: 00:00:00.09
SQL> select count(*) from t2 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
COUNT(*)
----------
90000
Elapsed: 00:00:00.02
SQL>
SQL> -- lets time one with tkprof
SQL> alter session set tracefile_identifier = 't1t2';
Session altered.
Elapsed: 00:00:00.00
SQL> alter session set events '10046 trace name context forever, level 12';
Session altered.
Elapsed: 00:00:00.00
SQL> -- add a comment to get a new plan
SQL> select /* 10195 OFF Q1 */ count(*) from t1 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
COUNT(*)
----------
90000
Elapsed: 00:00:00.10
SQL> select /* 10195 OFF Q2 */ count(*) from t2 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
COUNT(*)
----------
90000
Elapsed: 00:00:00.03
SQL> select /*+ rule 10195 OFF Q3 */ count(*) from t1 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
COUNT(*)
----------
90000
Elapsed: 00:00:00.02
SQL>
SQL> -- set 10195 event on again
SQL> alter session set events '10195 trace name context forever, level 1';
Session altered.
Elapsed: 00:00:00.01
SQL>
SQL> -- do queries again with new comments
SQL> select /* 10195 ON Q1 */ count(*) from t1 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
COUNT(*)
----------
90000
Elapsed: 00:00:00.03
SQL> select /* 10195 ON Q2 */ count(*) from t2 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
COUNT(*)
----------
90000
Elapsed: 00:00:00.02
SQL> select /*+ rule 10195 ON Q3 */ count(*) from t1 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
COUNT(*)
----------
90000
Elapsed: 00:00:00.03
SQL>
SQL> -- just for kicks, do the bad plan again
SQL> alter session set events '10195 trace name context off';
Session altered.
Elapsed: 00:00:00.01
SQL> select /* 10195 OFF_AGAIN Q2 */ count(*) from t2 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
COUNT(*)
----------
90000
Elapsed: 00:00:00.02
SQL> select /*+ rule 10195 OFF_AGAIN Q3 */ count(*) from t1 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
COUNT(*)
----------
90000
Elapsed: 00:00:00.03
SQL> select /* 10195 OFF_AGAIN Q1 */ count(*) from t1 where date_matched = to_date('12/31/4712','mm/dd/yyyy');
COUNT(*)
----------
90000
Elapsed: 00:00:00.09
SQL>
Subscribe to:
Posts (Atom)







